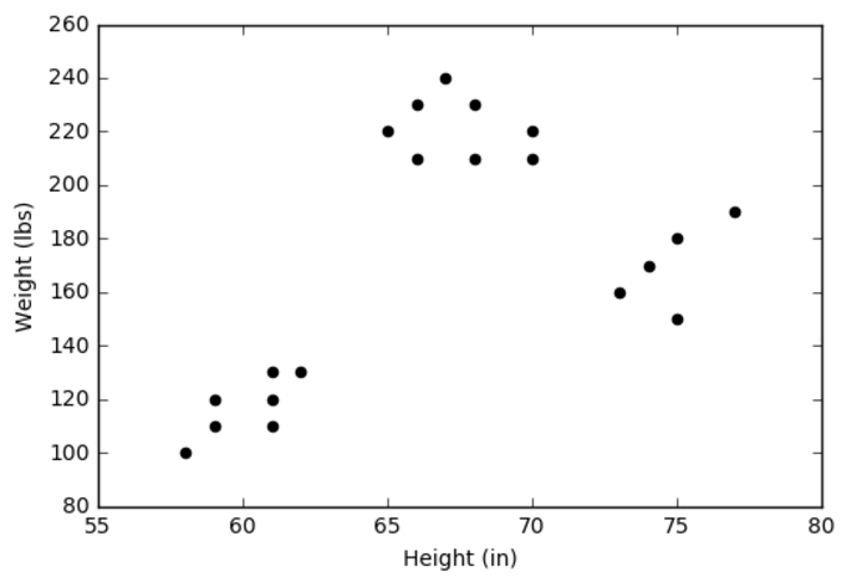
A Cross-Country A*
Last month’s column introduced and explored the basic A* algorithm within the cheeky context of a snake, a man, and a path to revenge. In this month’s post, the algorithm is extended to include terrain costs that take into account that different types of spots may be more expensive to traverse based on their nature (e.g., mountain, river, forest, desert, etc.). As in the simpler case already studied, the A* seeks to find the shortest path between a starting point and the goal when the latter is known but the best way to travel is not.
It is important to remember that at the core of the A* algorithm is the idea of an open spot. An open spot is a location adjacent to the current spot that the algorithm is visiting. From the vantage of the current spot, the neighboring spots can be examined and scored based on two criteria: the cost to move into that spot and a heuristic guess as to how far the spot is from the goal. These actions open the spot, which is placed on a list for future exploration. Once the A* has finished examining the neighborhood of the current spot, it closes that spot and selects the next spot to visit from among the lowest scoring spots on the list of open spots. By keeping pointers from open spots to the parent spots that opened them, the A* is able to back-track from the goal (once it has found it) to the beginning spot, thus determining the shortest path. The reader is encouraged to read the earlier post (An A* Drama) for more details.
As in the previous post, the material here is strongly influenced by Chapter 7 of AI for Game Developers, by David M. Bourg and Glenn Seemann.
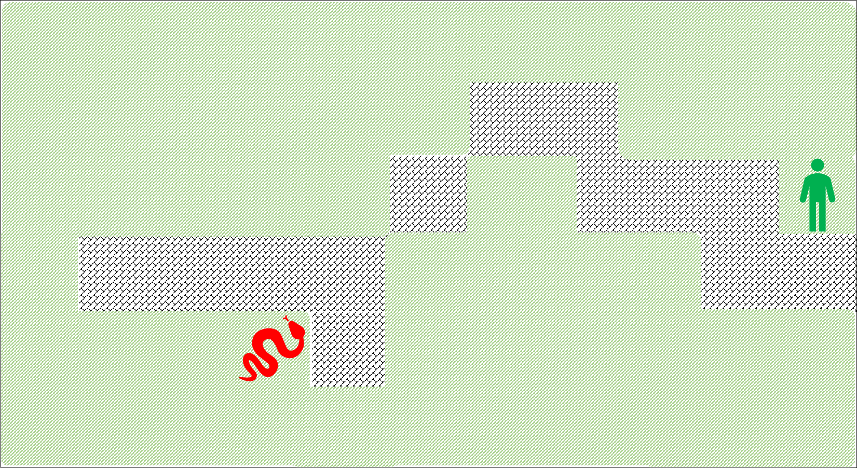
This month’s story begins with a wayfarer, who is journeying in the wilderness, looking for the shortest path home to his city.
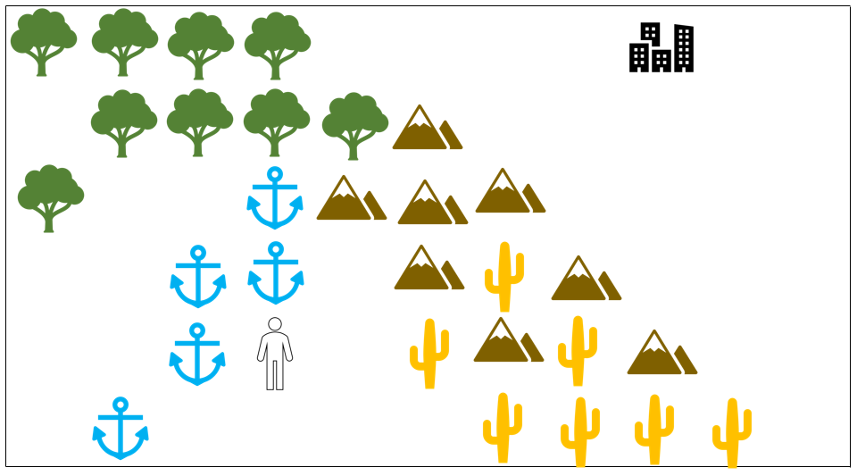
He weighs his options for path based not just on distance but on how well he can travel across each type of terrain. Normalizing his speed to the plain (blank of unfilled space), the wayfarer estimates that he can move 2 faster across the plain than through the forest, 5 times faster than crossing the water, 7 time faster than moving across the desert, and 10 times faster than climbing over the mountains. To evaluate his options he records his travel-time estimates and then lays a grid over his map to assist with his planning.
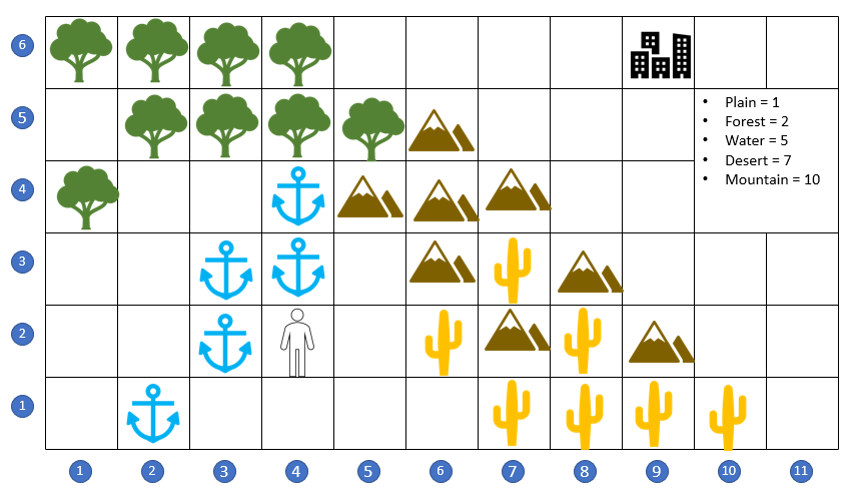
The mountain range to his north-east lies in a direct, as-the-crow-flies path from his current location at grid point (4,2) to the city at (9,6), but taking this route may not be the most time-optimal approach. He starts looking for ways to go around rather than over the mountain range.
By going through the desert to the east and south-east, he can head in roughly the ‘right’ direction and skirt the mountains completely, but the desert is not much cheaper than the mountains. He also considers going due north along the river course and then turning east in the forest, but a river trip is 5 times slower than in the plain. Finally he considers the possibility of going in the completely ‘wrong’ direction by heading to the south-west, where a ford allows him to cross the river on foot. Once on the other side, he can follow the flow upstream (to the north-east) until he enters the forest and can approach the city from the east. He scores these different possibilities and find that the last route is the cheapest.
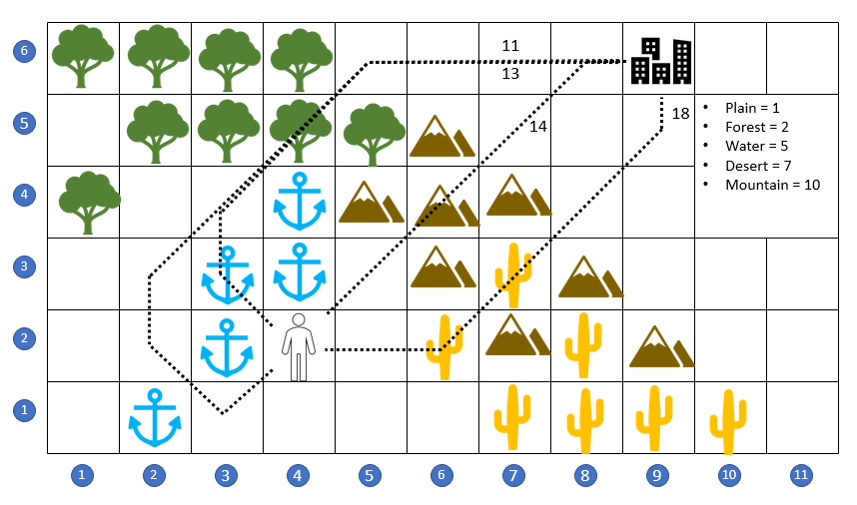
Given the same information, will the A* also find this over-the-river-and-through-the-woods path?
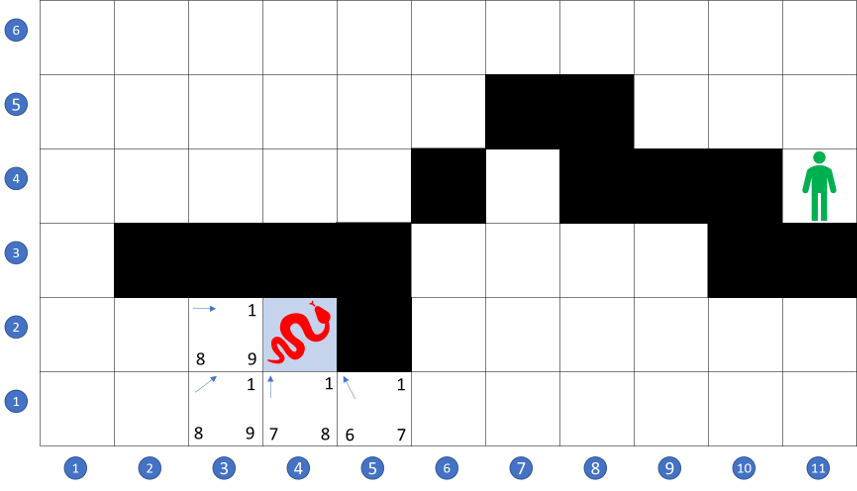
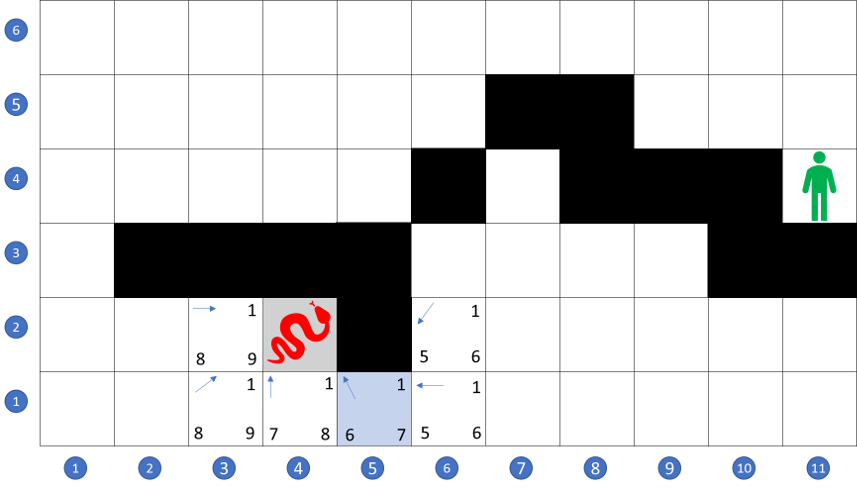
The first step to answering this question is to add the terrain cost to the A* algorithm. This is done by simply using the time-scaling the wayfarer had already noted to the local score when a spot is opened. For example, when the search begins, the A* starts at (4,2) and opens the 8 locations surrounding that spot. Grid locations (4,3), (3,3), and (3,2) are assigned a local cost of 5 since they are river spots. The remaining five spots ((3,1), (4,1), (5,1), (5,2), and (5,3)) are assigned a local cost of 1 since they are plain spots.
The heuristic scoring for the remaining cost is calculated as it was in the previous case as simply the as-the-crow-flies distance; that is to say that no regard is paid to terrain cost or even if the spot is available for traversal. It turns out that as long as all spots are scored on even footing with a common heuristic, the details of the scoring don’t matter.
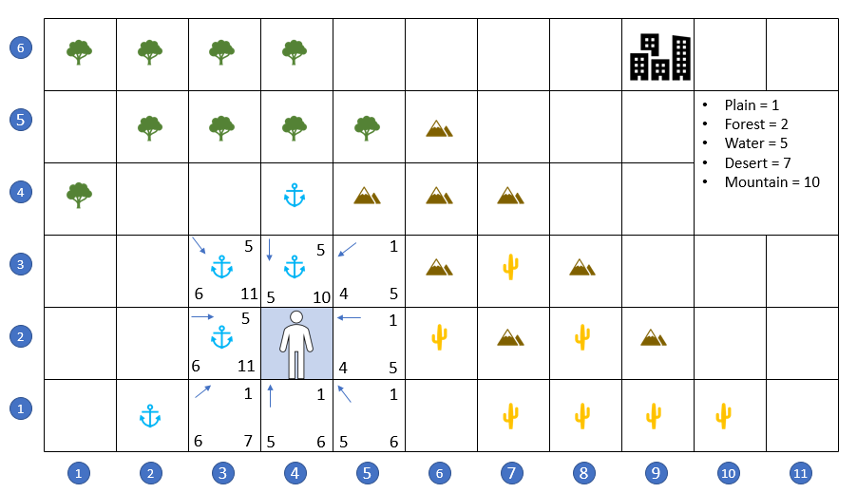
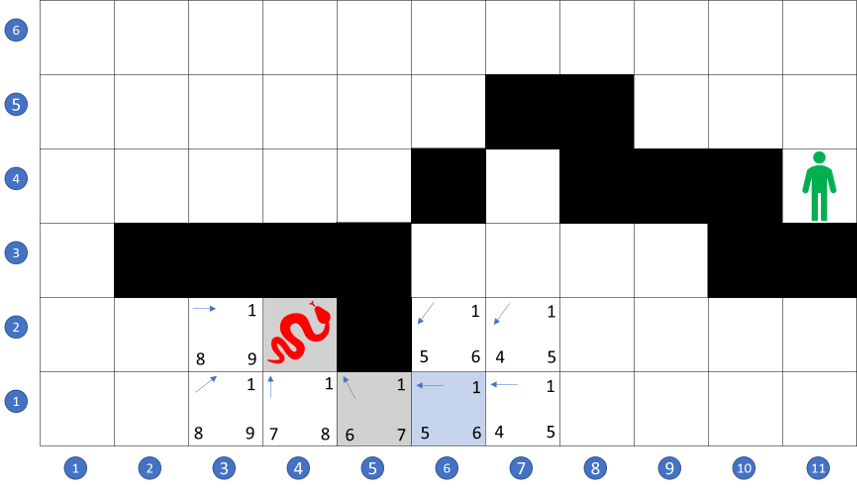
Initially, the A* flirts with moving to the north-east since the local costs are low (being plains) and the total cost is low since the path is moving in the correct direction. But quickly, the A* loses interest in these paths since their score, once opened, places them near the bottom of the open list.
After some exploration, the A* settles in on the path across the river, up along the western shore, through the forest to the north, and straight on to the east, thus bypassing the mountains and desert completely.
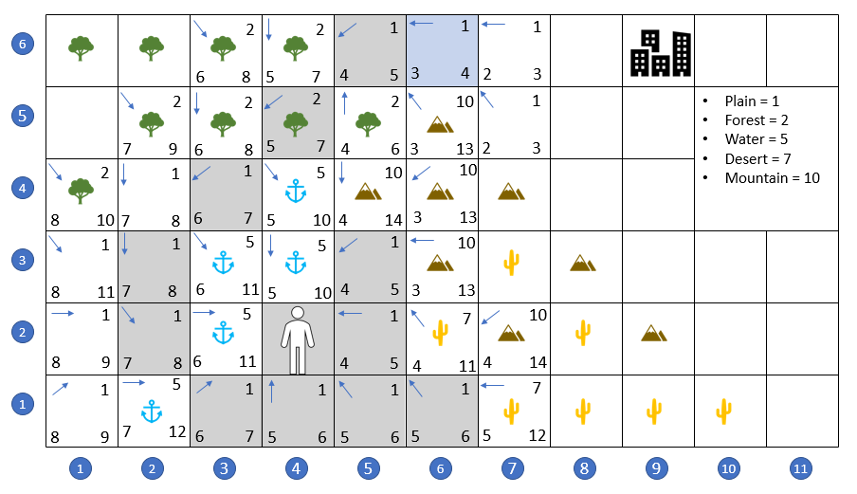
At this point, the A*, can pick either (7,5) or (7,6) as the next spot with no penalty, since both take the same amount of time in this geometry. The selection for equally-scored spots is random so A* can meander a bit picking between any of the following paths:
- (6,6) -> (7,6) -> (8,6) -> goal (9,6)
- (6,6) -> (7,6) -> (8,5) -> goal (9,6)
- (6,6) -> (7,5) -> (8,5) -> goal (9,6)
- (6,6) -> (7,5) -> (8,6) -> goal (9,6),
since they are all equivalent. For simplicity, I’ve coaxed the A* into the first of the list paths in the movie below but as far as our wayfarer is concerned, he gets home as safely by relying on A* as he does by his own skills as a world-weary traveler.