
Bare Bones Halting
It’s a rare thing to find a clear and simple explanation for something complicated – something like the Pythagorean Theorem or calculus or whatnot. It’s even rarer to find a clear and simple explanation for something that challenges the very pillars of logic – something like Gödel’s Theorem or the halting theorem. But J. Glenn Brookshear treats readers of his text Computer Science: An Overview to a remarkably clear exploration of the halting theorem in just a scant 3 pages in Chapter 12. I found this explanation so easy to digest that I thought I would devote a post to it, expanding on it in certain spots and putting my own spin on it.
Now to manage some expectations: it is important to note that this proof is not rigorous; many technical details needed to precisely define terms are swept under the rug; but neither is it incorrect. It is logically sound if a bit on the heuristic side.
The halting theorem is important in computer science and logic because it proves that it is impossible to construct an algorithm that is able to analyze an arbitrary computer program and all its possible inputs and determine if the program will run to a successful completion (i.e. halt) or will run forever, being unable to reach a solution. The implications of this theorem are profound since its proof demonstrates that some functions are not computable and I’ve discussed some of these notions in previous posts. This will be the first time I’ve set down a general notion of its proof.
The basic elements of the proof are a universal programing language, which Brookshear calls Bare Bones, and the basic idea of self-referential analysis.
The Bare Bones language is a sort of universal pseudocode to express those computable functions that run on a Turing Machine (called Turing-computable functions). The language, which is very simple, has three assignment commands:
- Clear a variable
- Increment a variable
- Decrement a variable
In addition, there is one looping construct based on the while loop that looks like
while x not 0 do; ... end;
While primitive, these commands make it possible to produce any type of higher level function. For example, Brookshear provides an algorithm for computing the product of two positive integers:

Note: for simplicity only positive integers will be discussed – but the results generalize to any type of computer word (float, sign int, etc.).
Now Bare Bones is a universal language in the sense that researchers have demonstrated that all Turing-computable functions can be expressed as Bare Bones algorithms similar to the Multiply function shown above. Assuming the Church-Turing thesis, which states that the set of all computable functions is the same as the set of all Turing-computable functions, allows one to conclude that Bare Bones is sufficiently rich to encode all algorithms that express computable functions.
One particularly important Bare Bones algorithm is something I call x-test (since Brookshear doesn’t give it a name).

The job of x-test is simple: it either terminates when x is identically zero or it runs forever otherwise.
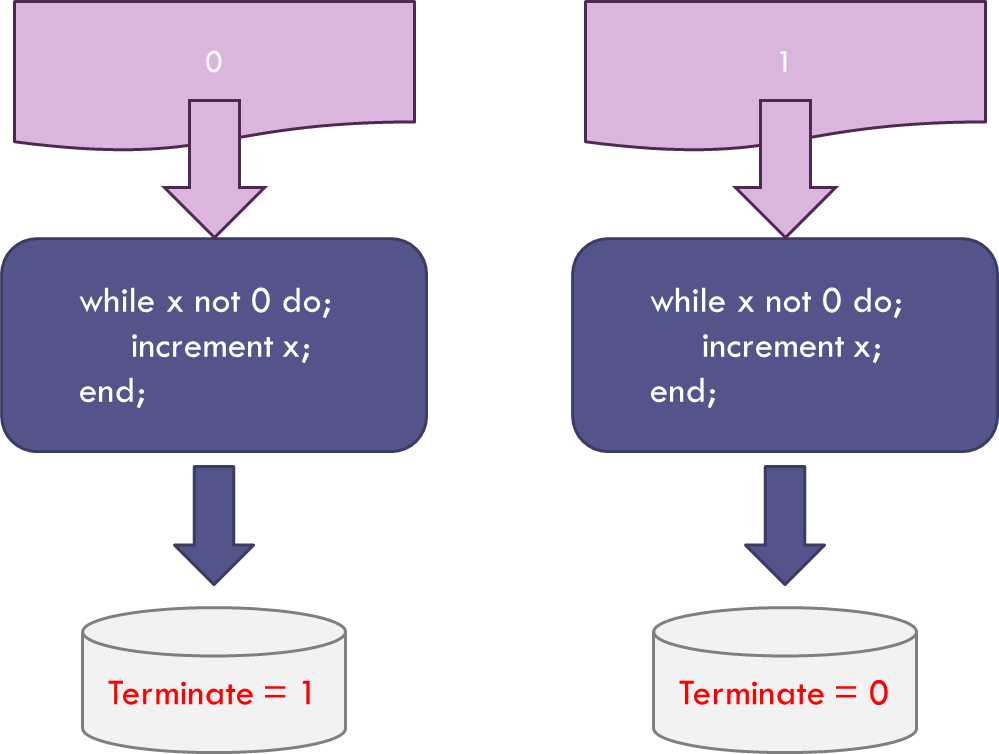
The Terminate flag is assigned a value of 0 if x-test fails to halt and 1 if it does.
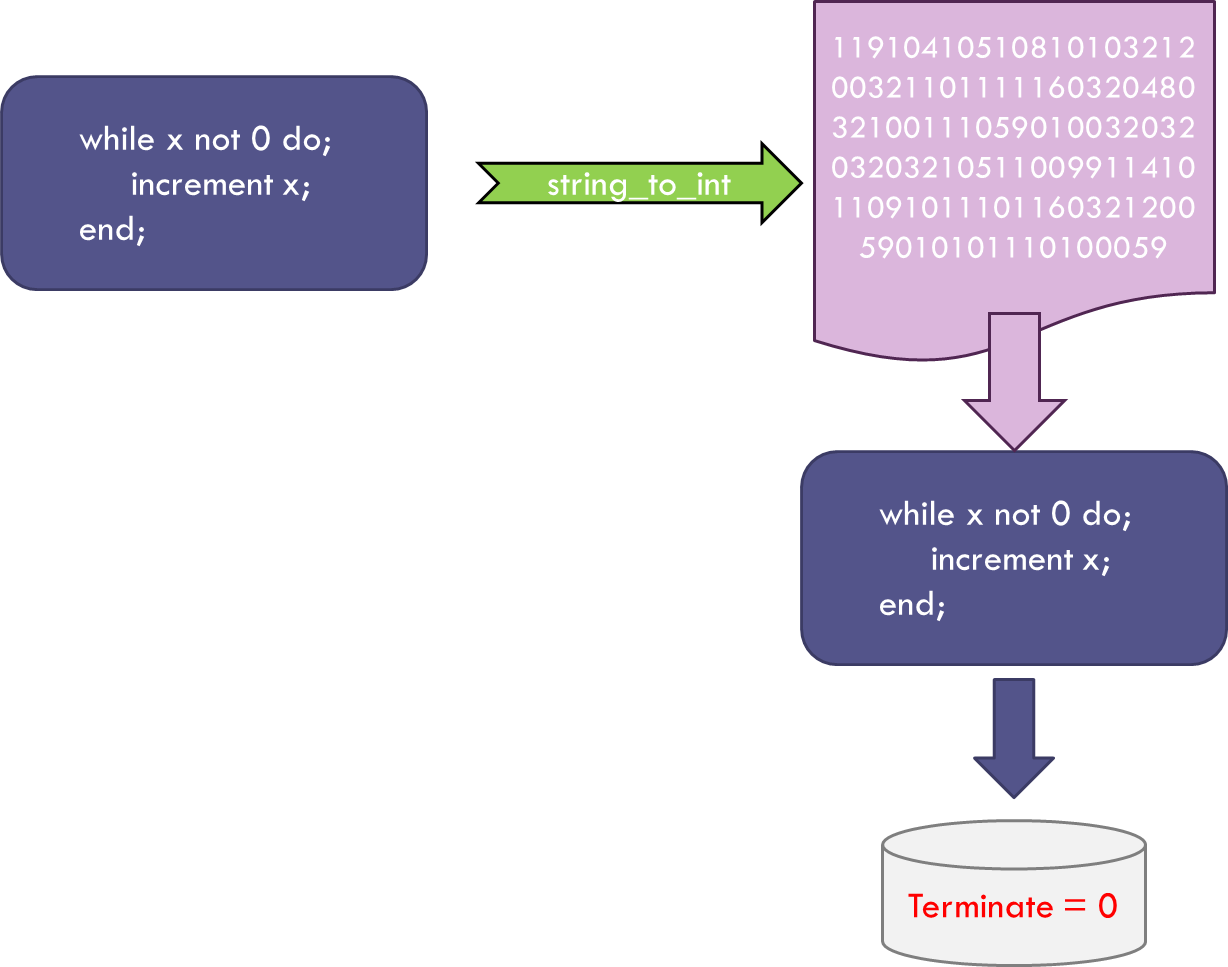
The next step brings in the concept of self-reference. The function x-test takes an arbitrary integer in and gives the binary output or 0 or 1. Since x-test is expressed as a set of characters in Bare Bones and since each character can be associated with an integer, the entire expression of x-test can be associated with an integer. To be concrete, the string representation of x-test is:
‘while x not 0 do;\n increment x;\nend;’
A simple python program, called string_to_int:
def string_to_int(s):
ord3 = lambda x : '%.3d' % ord(x)
return int(''.join(map(ord3, s)))
transforms this string to the (very long) integer
119104105108101032120032110111116032048032100111059010032032032032105110099114101109101110116032120059010101110100059
Using this integer in x-test results in the Terminate flag equal 0.
Of course, any expression of x-test in any programming language will result in a nonzero integer and so x-test never has a chance to terminate.
But there are clearly functions that do terminate when they are expressed as input for their own execution (one obvious example is the duel function to x-test where the while loop stops if x is non-zero). Such functions are said to be self-terminating.
Although it may look like a lot of effort for nothing, this notion of self-terminating functions is the key to the halting theorem and all that remains is to combine the above results with some clever thinking.
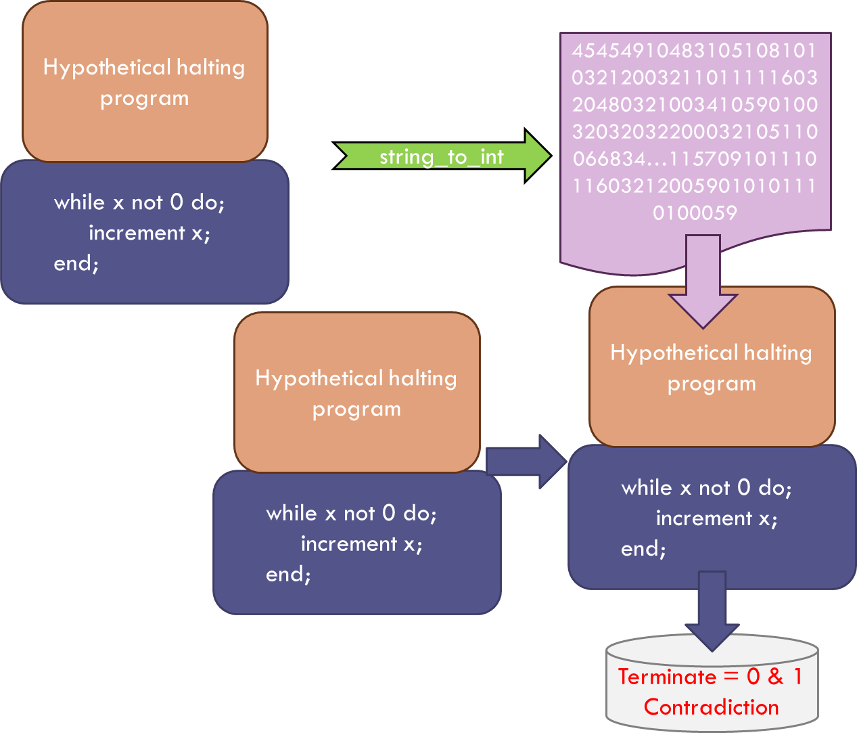
The clever thinking starts with the assumption that there exists a function, which I call the Hypothetical Halting Program (HHP), that can analyze any arbitrary program written in Bare Bones along with any corresponding input and determine which combinations will terminate (decidable) and which will not (undecidable).
Again, to be concrete, let’s look at what the HHP would do when looking to see if x-test is self-terminating.
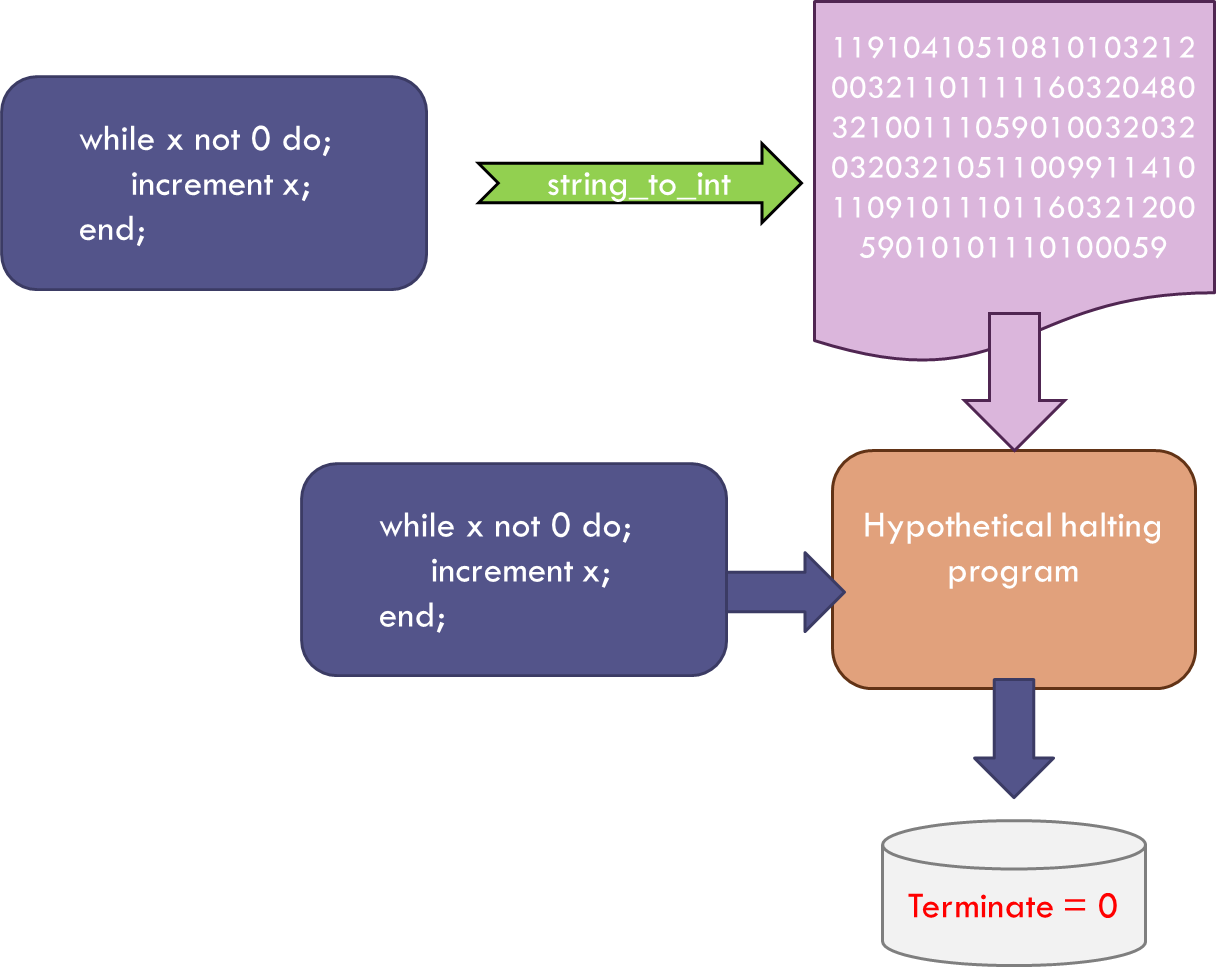
The HHP would be given the x-test function and the corresponding input (x-test in integer form) and would determine, just as we did above, that x-test won’t terminate – that is, x-test is not self-terminating.
Now such a function that works only on x-test is easy to understand; the text above that argued against x-test being self-terminating is one such instantiation. However, the goal is to have the HHP be abale to analyze all such algorithms so that we don’t have to think. Already, warning bells should be going off, since the word ‘all’ is a pretty big set, in fact infinite, and infinite sets have a habit of behaving badly.
But let’s set aside that concern for the moment and just continue our assumption that HHP can do the job. As we progress, we’ll see that our assumption of the existence of the HHP will lead to a contradiction that rules out this assumption and, thus, gives the desired proof. Operating without this foresight, we argue that since the HHP is computable it must be able to find expression as a Bare Bones program. And since the HHP analyzes Bare Bones programs, it must be able to analyze itself and determine if it is self-terminating – spitting out a 1 if so and a 0 otherwise.
Now we can construct a new program, called the HHP++, that is the sequential running of the HHP followed by x-test.
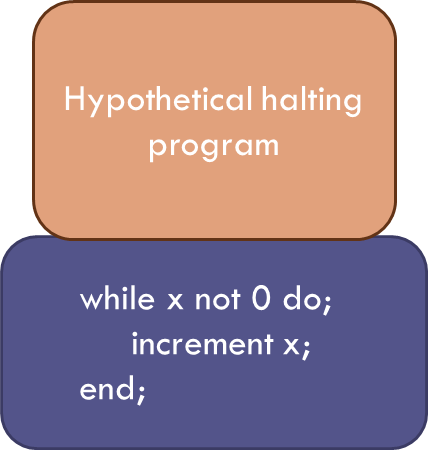
We can always do this in Bare Bones by first running HHP and then assigning its output (0 or 1) to the input of x-test. And here is where it gets interesting.
Take the HHP++ and let it test itself to see if it is self-terminating. If it is self-terminating, the HHP piece will confirm it so and will output a value of 1. This value is then passed to the x-test piece which then falls to halt. If the HHP++ is not self-terminating, the HHP piece will output a 0 which, when passed to the x-test piece, halts the operation. Thus the HHP++ is a program that is neither self-terminating nor not self-terminating and so the only way that can be true is that our original assumption that the HHP exists is false.
It is remarkable that using such a simple argument, the human mind is able to rule out the possibility of general function like the HHP.


